Operations basics¶
Use cases¶
The use cases modeled here describe the interactions between aitflow and the PDS crawler to perform various tasks related to ingestion, extraction, transformation, and report generation for PDS data collections.
The use cases identify user goals and the tasks they must perform to achieve those goals, providing a comprehensive overview of the PDS crawler’s requirements.
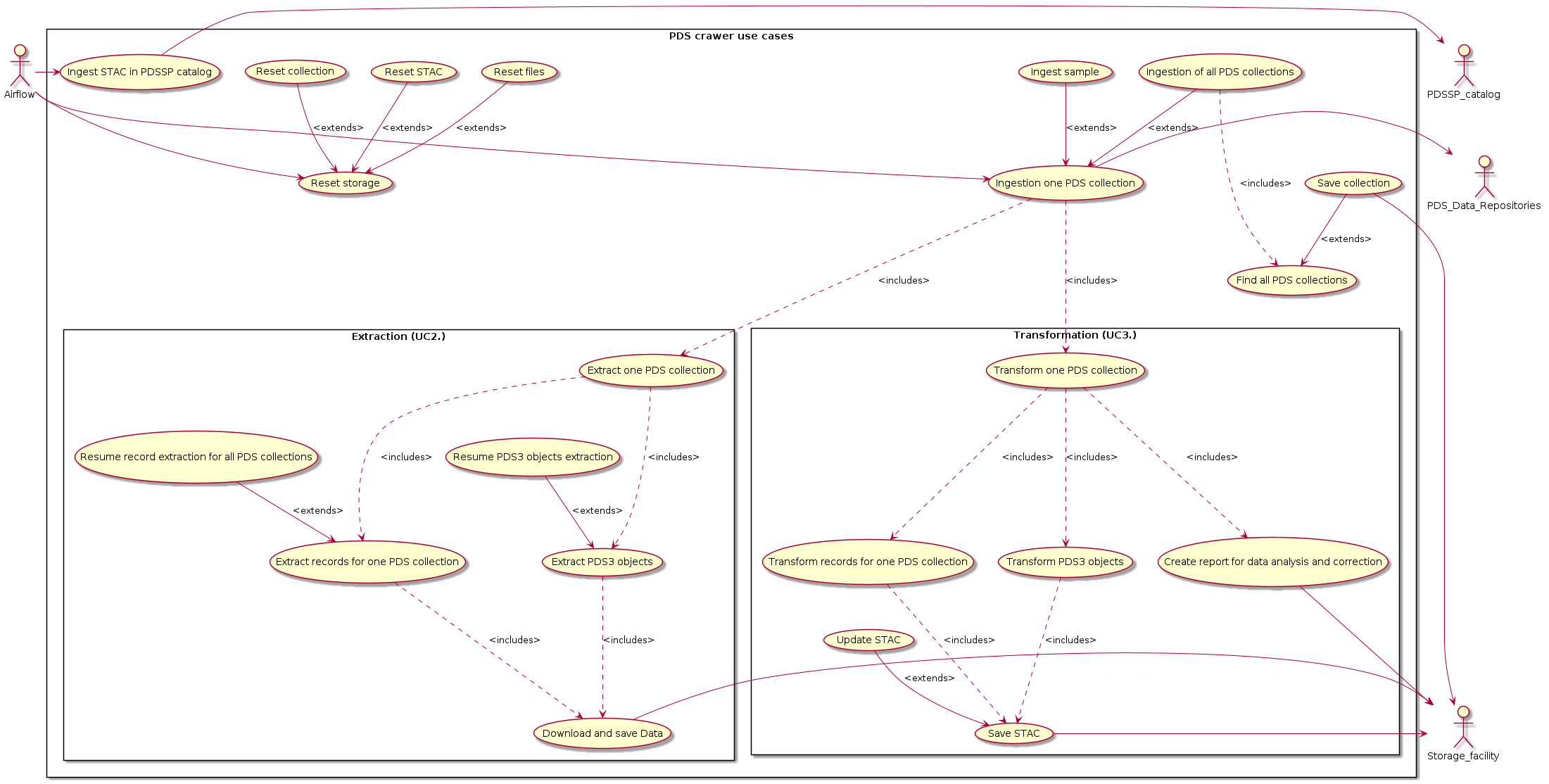
The following sections describe the main functions.
Main use case : UC 1 - Ingestion of one PDS collection¶
Use case Title |
Ingestion of one PDS Collection |
|---|---|
Description |
This use case addresses the need to ingest one PDS (Planetary Data System) collection into a system for further processing and analysis. |
Actors |
PDS crawler, PDS Data Repositories |
Preconditions |
|
Steps |
|
Postconditions |
|
Alternate Flows |
If a records cannot be downloaded or processed, an error message is generated and the system moves on to the next available collection. |
Exception Flows |
|
Notes |
The transformation process may involve several sub-steps, such as data cleaning, normalization, and feature engineering, depending on the specific requirements of the analysis. |
Sub use case : UC 1.1 - Ingestion of all PDS collections¶
Use case Title |
Ingestion of all PDS Collections |
|---|---|
Description |
This use case is an extension of UC 1 - Ingestion of one PDS collection. This use case addresses the need to ingest all PDS (Planetary Data System) collections into a system for further processing and analysis. |
Actors |
PDS crawler, PDS Data Repositories |
Preconditions |
|
Steps |
|
Postconditions |
|
Alternate Flows |
If a collection cannot be downloaded or processed, an error message is generated and the system moves on to the next available collection. |
Exception Flows |
|
Notes |
The transformation process may involve several sub-steps, such as data cleaning, normalization, and feature engineering, depending on the specific requirements of the analysis. |
Sub use case : UC 1.2 - Find all PDS collections¶
Use case Title |
Find all PDS collections |
|---|---|
Description |
This use case addresses the need to find all georeferenced PDS (Planetary Data System) collections for further downloading. |
Actors |
PDS crawler, ODE web service |
Preconditions |
|
Steps |
|
Postconditions |
|
Alternate Flows |
If a collection cannot be processed, an error message is generated and the system moves on to the next available collection. |
Exception Flows |
|
Notes |
User manual of ODE web service : https://oderest.rsl.wustl.edu/ODE_REST_V2.1.pdf |
Sub use case : UC 1.3 - Ingest sample¶
Use case Title |
Ingest sample |
|---|---|
Description |
This use case is an extension of UC 1 - Ingestion of one PDS collection. This use case addresses the need to retrieve a subset of the collection. |
Actors |
PDS crawler, PDS Data Repositories |
Preconditions |
|
Steps |
|
Postconditions |
|
Alternate Flows |
If a records cannot be downloaded or processed, an error message is generated and the system moves on to the next available collection. |
Exception Flows |
|
Notes |
The transformation process may involve several sub-steps, such as data cleaning, normalization, and feature engineering, depending on the specific requirements of the analysis. |
Sub use case : UC 1.4 - Save collection¶
Use case Title |
Save collection |
|---|---|
Description |
This use case is an extension of UC 1.2 - Find all PDS collections. This use case addresses the need to save the current collection in the PDS crawler storage in order to be able to search for it and process it completely in case of an error. |
Actors |
PDS crawler |
Preconditions |
The PDS crawler has sufficient storage capacity to store the ingested data. |
Steps |
|
Postconditions |
The collection is available in the HDF5 file of the PDS crawler’s storage. |
Alternate Flows |
If the collection has already saved, the collection is not saved. |
Exception Flows |
|
Main use case : UC 2 - Extraction of one collection¶
Use case Title |
Extraction of one collection |
|---|---|
Description |
This use case addresses the need to extract PDS information from the PDS Data Repositories. |
Actors |
PDS crawler, PDS Data Repositories |
Preconditions |
|
Steps |
|
Postconditions |
|
Alternate Flows |
If the collection cannot be downloaded or processed, an error message is generated and the system continues. |
Exception Flows |
|
Sub use case : UC 2.1 - Extract records for one PDS collection¶
Use case Title |
Extract records for one PDS collection |
|---|---|
Description |
This use case addresses the need to extract the georeferenced records from the PDS (Planetary Data System) collection for further transforming them to STAC format. |
Actors |
PDS crawler, ODE web service |
Preconditions |
|
Steps |
|
Postconditions |
|
Alternate Flows |
If the ODE web service is inaccessible or unavailable, the PDS crawler generates an error message and waits for the repositories to become available again. |
Exception Flows |
After a number of unsuccessful configurable attempts, the PDS crawler generates an error message and the PDS crawler moves on to the next available collection. |
Notes |
|
Sub use case : UC 2.2 - Extract PDS3 objects¶
Use case Title |
Extract PDS3 objects |
|---|---|
Description |
PDS3 catalog objects contain information about the mission, the plateform, the instrument and the dataset. These information are more detailed that those provided by the ODE web service. These objets are available on the the PDS dataset browser. |
Actors |
PDS crawler, PDS dataset browser |
Preconditions |
|
Steps |
|
Postconditions |
|
Alternate Flows |
If the ODE web service is inaccessible or unavailable, the PDS crawler generates an error message and waits for the repositories to become available again. |
Exception Flows |
After a number of unsuccessful configurable attempts, the PDS crawler generates an error message and the PDS crawler moves on to the next available collection. |
Notes |
|
Sub use case : UC 2.3 - Resume record extraction for all PDS collections¶
Use case Title |
Resume record extraction for all PDS collections |
|---|---|
Description |
This use case addresses the need to fully or partially reprocess all unprocessed downloaded responses from the ODE web service. |
Actors |
PDS crawler, ODE web service |
Preconditions |
|
Steps |
|
Postconditions |
|
Alternate Flows |
If the ODE web service is inaccessible or unavailable, the PDS crawler generates an error message and waits for the repositories to become available again. |
Exception Flows |
After a number of unsuccessful configurable attempts, the PDS crawler generates an error message and the PDS crawler moves on to the next available collection. |
Notes |
|
Sub use case : UC 2.4 - Resume PDS3 objects extraction¶
Use case Title |
Resume PDS3 objects extraction |
|---|---|
Description |
This use case addresses the need to fully or partially reprocess all unprocessed PDS3 objects in the collection |
Actors |
PDS crawler, PDS dataset browser |
Preconditions |
|
Steps |
|
Postconditions |
|
Alternate Flows |
If the ODE web service is inaccessible or unavailable, the PDS crawler generates an error message and waits for the repositories to become available again. |
Exception Flows |
After a number of unsuccessful configurable attempts, the PDS crawler generates an error message and the PDS crawler moves on to the next available collection. |
Notes |
|
Main use case : UC 3 - Transformation¶
Use case Title |
Transformation of one PDS Collection |
|---|---|
Description |
This use case addresses the need to transform the extracted collection in a STAC format. |
Actors |
PDS crawler |
Preconditions |
The extracted data is available in the PDS crawler’s storage. |
Steps |
|
Postconditions |
For each collection, a mission catalog, a plateform catalog, a instrument catalog, a collection and items are available on the PDS crawler’s storage. |
Alternate Flows |
If an error occurs when a collection is being processed, an error message is generated, notified, and the system moves on to the next available collection. |
Exception Flows |
None |
Notes |
STAC specifications : https://github.com/radiantearth/stac-spec/ |
Sub use case : UC 3.1 - Transform PDS3 objects from the collection¶
Use case Title |
Transform PDS3 objects from the collection |
|---|---|
Description |
PDS3 objects contain a wealth of information about the mission, platform, instrument and collection. This use case addresses the need to transform these information in a STAC format. |
Actors |
PDS crawler |
Preconditions |
The extracted data is available in the PDS crawler’s storage. |
Steps |
|
Postconditions |
a mission catalog, a plateform catalog, a instrument catalog and a collection are available on the PDS crawler’s storage. |
Alternate Flows |
If an error occurs while processing the collection, it is possible that no catalog is generated. If a catalog is missing, the system will notify the error |
Exception Flows |
None |
Notes |
STAC specifications : https://github.com/radiantearth/stac-spec/ |
Sub use case : UC 3.2 - Transform records from one PDS collection¶
Use case Title |
Transform records from one PDS collection |
|---|---|
Description |
This use case addresses the need to transform the extracted collection in a STAC format. |
Actors |
PDS crawler |
Preconditions |
The extracted data is available in the PDS crawler’s storage. |
Steps |
|
Postconditions |
items must be generated et enventualy the instrument, plateform, mission as well if these catalogs are not available. |
Alternate Flows |
If an error occurs when a collection is being processed, an error message is generated, notified, and the system continues |
Exception Flows |
None |
Notes |
STAC specifications : https://github.com/radiantearth/stac-spec/ |
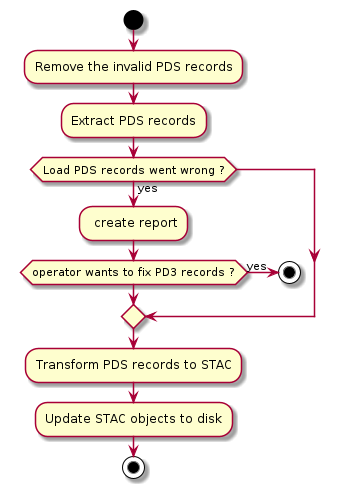
Operations¶
The main operations of the PDSSP crawler are the following
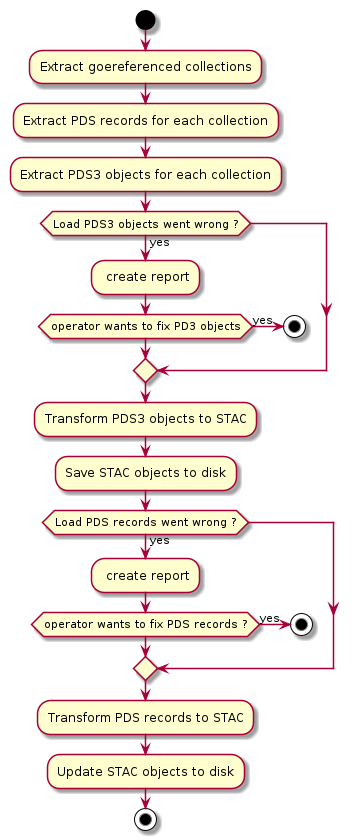
After fixing the PDS3 Objects, the operations are the following
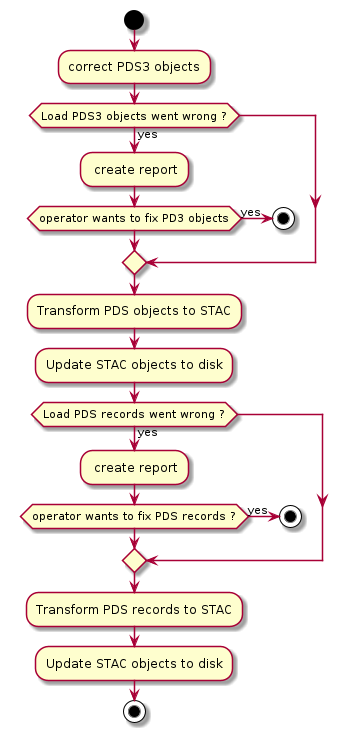
if there was a problem loading the PDS records, this indicates that the extraction of the PDS records went wrong. The operations are therefore as follows